延迟渲染
不管是传统管线还是光追管线,延迟渲染都是需要的,这里创建一个最简单的延迟渲染流程,主要是看看图像附件是怎么在多个renderPass间转移的。这节不是重点,写得很简略,仅作展示,所以代码都没有怎么封装,直接添加
创建 G-Buffer 渲染目标
创建额外的图像附件:
// 延迟渲染 GBuffer Attachments
std::unique_ptr<renderableImageAttachment> r_gbuffer_position;
初始化:
// Renderer::Init()
// G-buffer阶段图像附件
r_gbuffer_position = std::make_unique<renderableImageAttachment>();
r_gbuffer_position->Init(extent,
VK_FORMAT_R16G16B16A16_SFLOAT,
VK_IMAGE_USAGE_COLOR_ATTACHMENT_BIT,
VK_IMAGE_ASPECT_COLOR_BIT,
r_descriptorPool.get());
创建 G-Buffer RenderPass + Framebuffer
加入额外的RenderPass和Framebuffer,这里的初始化代码在Renderer::Init(),太长了而且和之前大同小异,只需要给subPass附加多个颜色附件,帧缓冲同样,就不放了
std::unique_ptr<renderPass> r_renderPass_gbuffer;
std::unique_ptr<framebuffer> r_framebuffer_gbuffer;
G-Buffer 渲染着色器 & 管线设置
需要新的管线:
std::unique_ptr<pipelineLayout> r_pipelineLayout_gbuffer;
std::unique_ptr<pipeline> r_pipeline_gbuffer;
这里没有什么特殊的,与之前一致
Light-Pass 管线设置
光线管线需要向其layout中传入所有g-buffer图像附件的descriptorSetLayout,并且我们不能像创建摄像机UBO描述符集那样,仅在初始化时调用:
r_descriptorSet_camera->Write(makeSpanFromOne(bufferInfo), VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER);
而是需要在图像被resize时,即Renderer::resizeImageFramebuffers(VkExtent2D newExtent)中重新写入
渲染
渲染逻辑也很简单,vulkan中可以在一个commandBuffer中连续录制多个Pass,首先是G-buffer Pass,绑定r_renderPass_gbuffer和r_pipeline_gbuffer,绘制场景,并写入需要的内容,这里只简单的写入了场景世界坐标作为测试。然后在光照Pass中,绑定G-buffer中的图像附件,绘制屏幕四边形,都是比较常规的内容
值得一提的重点是,和OpenGL不同,多个renderPass需要注意管线之间的屏障,也就是中间被注释掉的代码:
//管线屏障,等待 GBuffer 阶段结束
transitionAttachmentsToShaderRead(
r_commandBuffer->getHandle(),
{
r_gbuffer_position.get()
}
);
需要同步的对象显然是G-buffer阶段被写入的图像附件,其被G-buffer Pass写入,然后在同一帧被光照Pass读取,在OpenGL中我们不需要关心这个,但vulkan中要注意这里的同步。这段的代码用于显式的创建内存屏障,但在renderPass之间同步图像附件,还有一个更直接的方法,那就是使用renderPass的子通道依赖,所以后面会重点介绍一下子通道依赖,这里的函数作用是完全等价的,不启用子通道依赖而用这个也是可以的
子通道依赖
回到Renderer::Init()中两个RenderPass的创建过程中,对应的代码为:
// G-buffer Pass
VkSubpassDependency dependency_gbuffer{};
dependency_gbuffer.srcSubpass = VK_SUBPASS_EXTERNAL;
dependency_gbuffer.dstSubpass = 0;
dependency_gbuffer.srcStageMask = VK_PIPELINE_STAGE_BOTTOM_OF_PIPE_BIT;
dependency_gbuffer.dstStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT;
dependency_gbuffer.srcAccessMask = 0;
dependency_gbuffer.dstAccessMask = VK_ACCESS_COLOR_ATTACHMENT_WRITE_BIT;
// Light Pass
VkSubpassDependency dependency{};
dependency.srcSubpass = VK_SUBPASS_EXTERNAL;
dependency.dstSubpass = 0;
dependency.srcStageMask = VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT;
dependency.dstStageMask = VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT;
dependency.srcAccessMask = VK_ACCESS_COLOR_ATTACHMENT_WRITE_BIT;
dependency.dstAccessMask = VK_ACCESS_SHADER_READ_BIT;
前两个参数srcSubpass和dstSubpass不用管,在同一个Pass中有多个subPass才需要这个,我们也可以选择将G-buffer和Light放在一个Pass里,不过应该不常见
后面的参数可以分组来看,即srcStageMask和srcAccessMask表示前一个Pass在哪个阶段完成了哪些资源的访问,dstStageMask和dstAccessMask表示当前Pass在哪个阶段可以安全开始访问哪些资源
以Light Pass为例,含义就是:G-buffer pass(前一个Pass)的颜色附件写入阶段(VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT)完成了对图附件的写入(VK_ACCESS_COLOR_ATTACHMENT_WRITE_BIT),Light Pass(当前Pass)才会在片段着色器(VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT)读取纹理(VK_ACCESS_SHADER_READ_BIT)
下面是VK_PIPELINE_STAGE和VK_ACCESS系列枚举项的解释:
| 阶段枚举 | 含义 |
|---|---|
VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT | 渲染管线最前面(还没开始) |
VK_PIPELINE_STAGE_DRAW_INDIRECT_BIT | 发起绘制调用 |
VK_PIPELINE_STAGE_VERTEX_INPUT_BIT | 顶点输入 |
VK_PIPELINE_STAGE_VERTEX_SHADER_BIT | 顶点着色器 |
VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT | 片元着色器 |
VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT | 写颜色附件的阶段(最常用) |
VK_PIPELINE_STAGE_COMPUTE_SHADER_BIT | 计算着色器阶段 |
VK_PIPELINE_STAGE_TRANSFER_BIT | 用于 vkCmdCopy... 系列命令 |
VK_PIPELINE_STAGE_BOTTOM_OF_PIPE_BIT | 管线结束,表示所有操作都完成 |
VK_PIPELINE_STAGE_ALL_COMMANDS_BIT | 所有命令,最保守的同步方式 |
| 访问枚举 | 含义 |
|---|---|
VK_ACCESS_INDIRECT_COMMAND_READ_BIT | 读取间接命令 |
VK_ACCESS_INDEX_READ_BIT / VERTEX_ATTRIBUTE_READ_BIT | 读取顶点或索引缓冲区 |
VK_ACCESS_UNIFORM_READ_BIT | 读取 Uniform Buffer |
VK_ACCESS_SHADER_READ_BIT / SHADER_WRITE_BIT | 着色器读取 / 写入 SSBO/纹理等 |
VK_ACCESS_COLOR_ATTACHMENT_READ/WRITE_BIT | 颜色附件读写(如 G-buffer) |
VK_ACCESS_DEPTH_STENCIL_ATTACHMENT_READ/WRITE_BIT | 深度模板缓冲读写 |
VK_ACCESS_TRANSFER_READ/WRITE_BIT | 传输操作读写 |
VK_ACCESS_MEMORY_READ/WRITE_BIT | 所有类型的读写,最保守的方式 |
常见组合:
| 用途 | srcStageMask | dstStageMask | srcAccessMask | dstAccessMask |
|---|---|---|---|---|
| 清屏 → 渲染 | BOTTOM_OF_PIPE | COLOR_ATTACHMENT_OUTPUT | MEMORY_READ | COLOR_ATTACHMENT_WRITE |
| 写 G-Buffer → 采样 | COLOR_ATTACHMENT_OUTPUT | FRAGMENT_SHADER | COLOR_ATTACHMENT_WRITE | SHADER_READ |
| Compute Pass → 渲染 Pass | COMPUTE_SHADER | VERTEX_SHADER or FRAGMENT_SHADER | SHADER_WRITE | SHADER_READ |
| Transfer → 着色器采样 | TRANSFER | FRAGMENT_SHADER | TRANSFER_WRITE | SHADER_READ |
再回去看注释掉的函数,应该就非常清晰了,功能是一样的
构建
用到了两个额外的着色器Deferred_G和Deferred_L,其本身是迷惑行为,因为Deferred_L自己就能拿到世界坐标,没必要通过g-buffer来传入,如何构建合理且完整的延迟渲染,我在上一个教程有实现,本教程注重API和光线追踪,所以这里只是举例
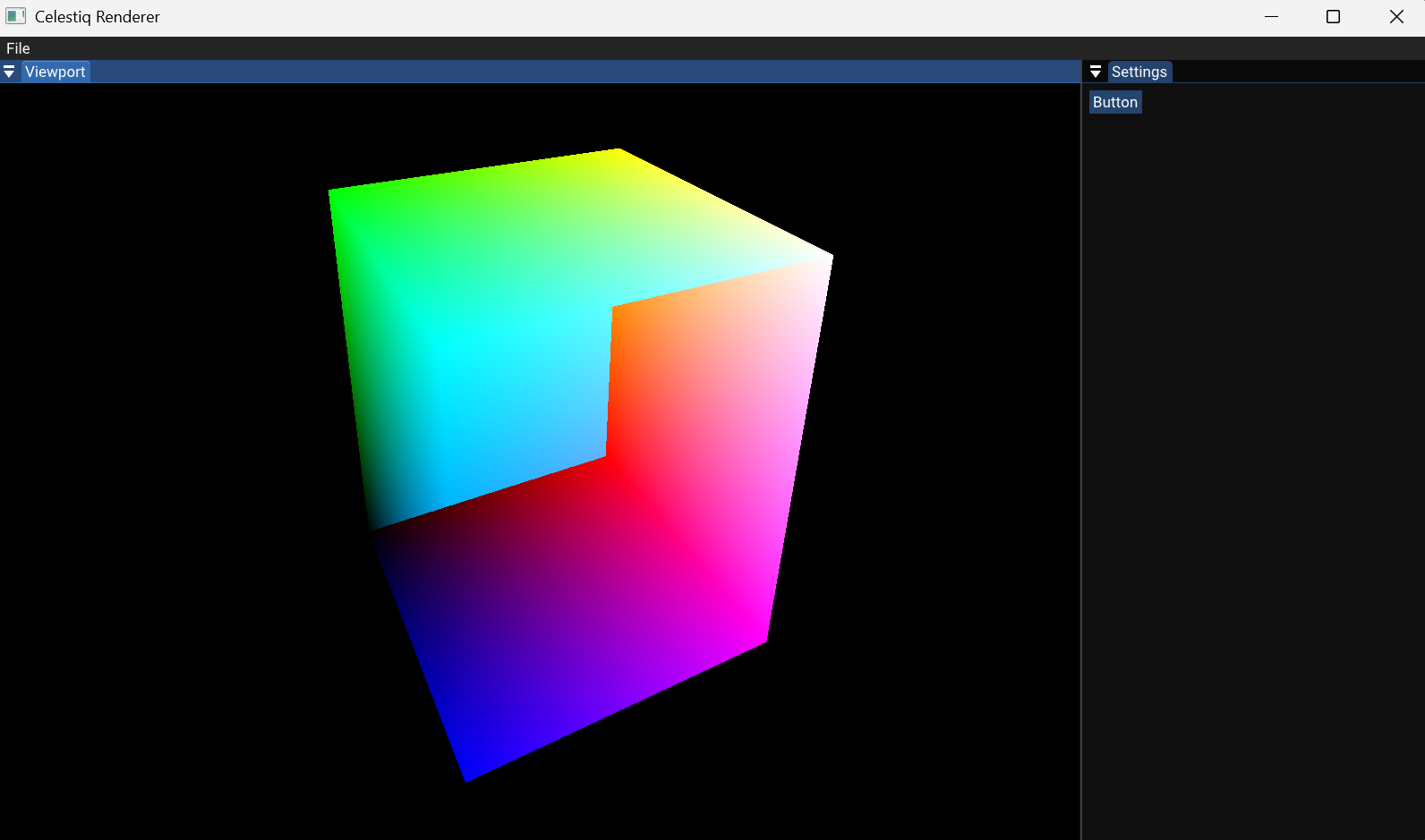
构建可以看到下面的效果,世界坐标被渲染,缺少深度剔除。想要开启的话,需要在创建G-buffer管线时设置,并且向frameBuffer中添加深度附件,对于教程后面的部分没什么必要,就不浪费时间了
代码存档
代码下载